Exploring Expressions of Emotions in GitHub Commit Messages
Last week GitHub announced that the data collected over at the GitHub Archive was made available as a public dataset on Google's BigQuery web service. Pretty exciting news for data analysts, considering that the timeline dataset currently contains more than 7 million records and is growing quickly.
To see what developers come up with analyzing the GitHub timeline and language correlation datasets, they started a data challenge which is open for submissions until May 21st.
Being interested in both natural and programming languages, I decided to expand on an analysis of profanity in git commit messages per programming language by Andrew Vos with a more general exploration of expressions of emotions as well as looking at messages indicating issues and those containing swear words.
Method of Collecting and Analyzing Data
Reading millions of commit messages and categorizing them is certainly not a task I'd be able to accomplish in less than 3 weeks and honestly wouldn't want to. Instead, I assembled lists of words expressing emotions using the resources listed at the bottom of this article and wrote corresponding database queries to count occurrences of these words grouped by programming languages.
Then for each language I calculated the percentage of messages that meet the criteria, i. e. contain certain expressions, in relation to the total number of commits for that language. Only non-empty commit messages of projects with an assigned language were included.
Since the number of commits varies considerably across different languages only those with at least 40,000 commits in the analyzed time frame were accounted for, resulting in a total of of 2,526,650 commit messages within the set of languages displayed in the bar chart below:
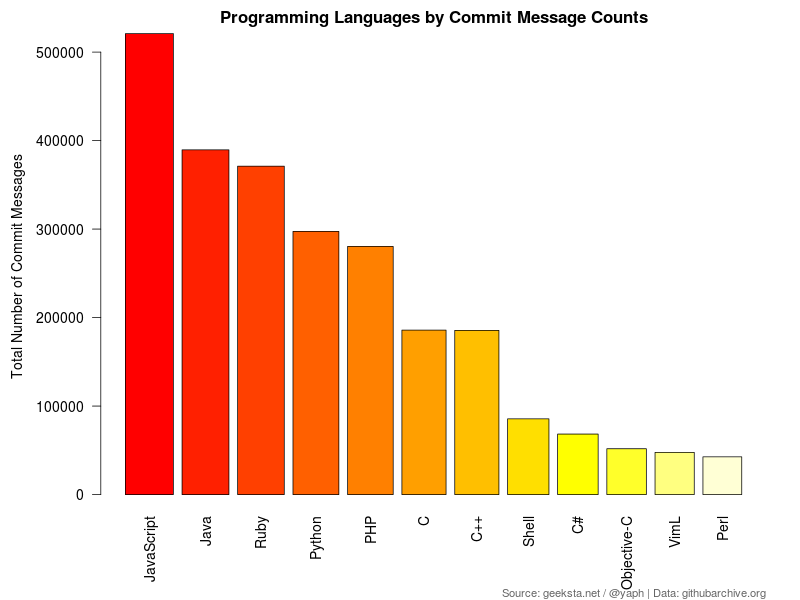
Even though a minimum of 40,000 samples per languages seemed adequate to me (I wanted to include Perl), different sample sizes result in varying accuracy, which is a problem and a bit like comparing apples and oranges. Statisticians will probably deny any value of such an approach, still I think it can serve to develop some hypotheses.
Actually, this is not the only problem. Assuming a particular emotion just because a message contains a certain expression does not work in many cases. The expression does not necessarily refer to the person who wrote the message, moreover, natural language is full of ambiguity, there are rhetorical devices like irony, and messages can be written in other languages than English, where the same word may have a completely different meaning.
So to make sure that my approach is not completely messed up, I spent quite some time looking through the resulting messages, refined the queries and excluded many phrases with too much ambiguity. Still, I anticipate that there is no conclusion, this is solely a descriptive study, take it with a grain of salt and enjoy reading the example messages ;)
Emotions, Issues, Swearing
The rest of this article is divided into sections for the analyzed emotions: anger, joy, amusement and surprise. Additionally there are two separate sections for messages indicating issues and messages containing swear words, which likely indicate emotions, but you can't say which without further analysis.
Each of the following sections contains a regular expression used in the database query, a chart for the corresponding emotion, showing the percentages of commit messages per programming language, that match the expression, and a few example messages.
I do not link to the individual commits, as the URLs appear truncated in the GitHub Archive dataset. I presume you know how to use search engines, if you really want to track down a particular message.
One last warning before you go on reading at your workplace: this article, most notably the part about swearing, contains more than seven dirty words.
Anger
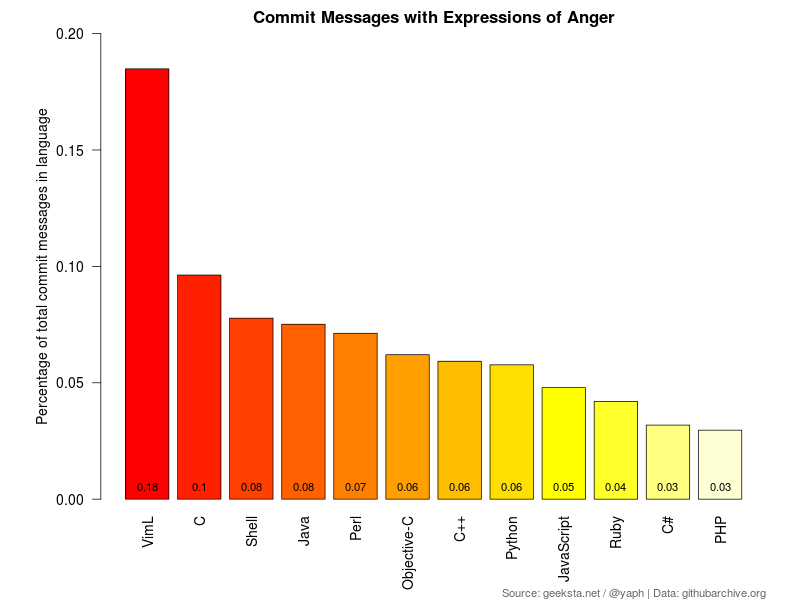
Let's start with anger, an emotion one would expect to be expressed rather frequently in commit messages, as things often go wrong and the process of tracking down bugs and fixing them can be pretty annoying.
What stands out in the anger chart compared to the rest is the prominent gap between the "most angry language" VimL and the other languages. No wonder that Vi is also referred to as the editor of the beast.
Regular Expression
(?i)\b(a+rgh|angry|annoyed|annoying|appalled|bitter|cranky|hate|hating|mad)\b'
Example Messages
- remove caveat section, I will write it later when I know what it is and can articulate without being bitter (Python)
- I hate you Internet Explorer. I hate you so much. (PHP)
- boy do I hate these fucking things (C++)
- Got mad, removed everything from top-level file. (C)
- Added another annoying bug that needs to be fixed (JavaScript)
- AAAARGH (JavaScript)
- HATE HATE HATE HATE HATE (C++)
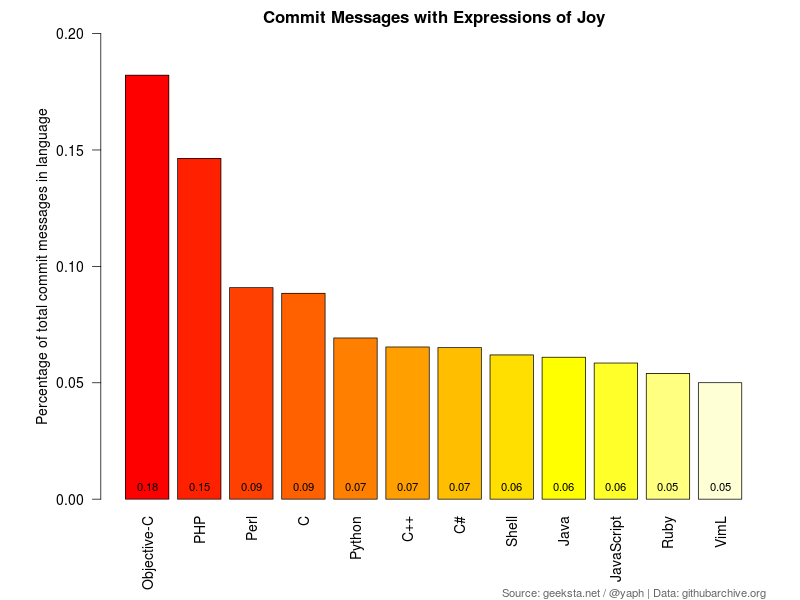
Joy / Elation
For similar reasons one can expect anger one can also expect joy. Commits often solve problems, which should make developers happy. While I'm at it, I decided to omit the word "happy" itself. It is used frequently, but often in phrases like "make X happy" or "X is happy", e. g. add readme to make github happy or in negations like tar is not happy on linux - grr, not really indicating a joyful experience.
Another edge case I excluded is the word "pleasant", often used in phrases like "pleasant to work with", which do convey some kind of joy, but also in "make something more pleasant", which does not, does it? While skimming through messages I found this nice example of irony, which I didn't want to keep for myself: regexes are fun and pleasant to work with, in the same way that oranges are purple.
Regular Expression
(?i)\b(yes|yay|hallelujah|hurray|bingo|amused|cheerful|excited|glad|proud)\b
Example Messages
- This is getting very interesting right now. I'm excited. (JavaScript)
- we we we so excited (JavaScript)
- I'm a moron. Really glad I have the test server. (JavaScript)
- I've added a feature :) #proud (C#)
- Recursive vs. Nonrecursive fibonacci number generator. ...yay... (C++)
- Yay, comments in code! (Java)
- omg massive update yay (Java)
- The PHP commit. Yes, THE one. (Python)
- fixed my code hallelujah (Python)
- Amazing awesome super bug fix hurray (Java)
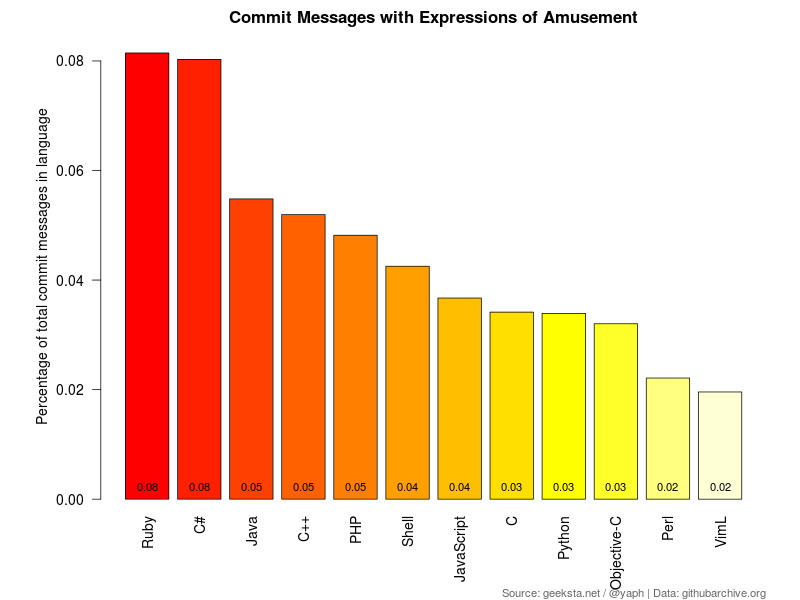
Amusement
To detect amusement I heavily relied on Internet slang expressions like "lol" or "rofl" and onomatopoeia like "haha" or "hehe". Looking at the numbers programming cannot be very amusing, but there are probably better ways to recognize this emotion.
Regular Expression
(?i)\b(ha(ha)+|he(he)+|lol|rofl|lmfao|lulz|lolz|rotfl|lawl|hilarious)\b
Example Messages
- rotfl :D (PHP)
- Hilarious new quote from America's favorite bigot. (Perl) - Editor's note: Yes, this refers to Santorum.
- Whoops. didn't patch it correctly. Hehe, I need to test things better... (Shell)
- haha! Rewrote basically the entire app. (Ruby)
- I have a direction now! haha! (JavaScript)
- HAHA, TAKE THAT, README! (C)
- Actually does what it says in the changelog now haha (Java)
- Added Test::utf8 just to be safe ;) hehe (JavaScript)
- Buffer overflows lol. (C)
- lol, I dunno what I'm doing (JavaScript)
- added a bunch of features lol I am so good at using version control properly (Ruby)
Surprise
My attempt to detect surprise, was the least satisfying regarding the low numbers, except for sadness which I left out for that reason. There would have been more surprise if I included "wow", but also more "World of Warcraft".
Still, I'm a bit surprised of the result, not because Perl is the winner, but because PHP does not seem to surprise people that often, which does not reflect my experience with this language at all.
Regular Expression
(?i)\b(yikes|gosh|baffled|stumped|surprised|shocked)\b
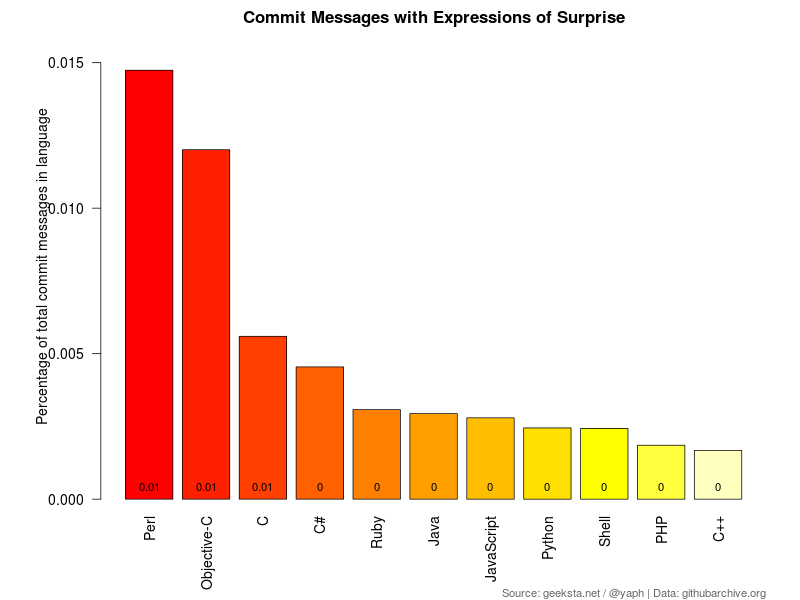
Example Messages
- Absolutely stumped as to why the post is not working (JavaScript)
- Stumped as to what I broke. (Objective-C)
- I'm surprised, but all test pass on 2.6, 2.7, 3.2, updating doc (Python)
- im surprised this works.. (C)
- try multi-line text print... (i'll be shocked if this works) (PHP)
- more stuff for the dev guys to test. gosh, its good to be a designer. (Ruby)
Issues / Bugs
Every developer knows that bugs creep into code all the time, so it's no surprise that messages about them are by far the most frequent ones compared to everything else in this analysis. Something that becomes even more apparent considering the few words I looked for.
A fun fact I have to add: 48.4% of all messages containing "IE", "InternetExplorer" or "Internet Explorer" also satisfy the issue detecting regex below. It's probably so few because I omitted the word problem.
Regular Expression
(?i)\b(bug|fix|issue)|corrected
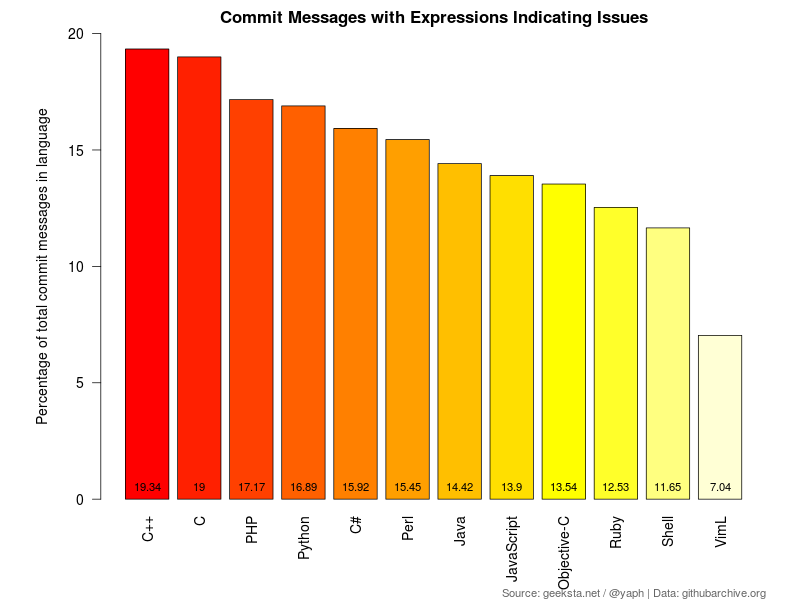
Example messages
- fixed that bug before it happened (JavaScript) - Editor's note: Impressive!
- real time stream - fix crass regular expression logic bug. (C)
- tried to fix attack animation. failed hard. (Java)
- Small css fixes for evil IE. (Python)
- It's hard to be a fool (fix for the fix) (C)
- fixed sound crashing firefox (Clojure)
- Fix: awful IE (PHP)
- hopefully this takes care of all the IE buggery. (PHP)
- fixed IE dom finickiness. (JavaScript)
Swearing (NSFW)
Now to the final and most hilarious part of this analysis: exploring occurrences of swear words, which likely indicate some kind of issue with the code, language, framework or whatever. The chart looks pretty balanced compared to the previous ones and VimL wins again.
Assembling a list of swear words is pretty hard. You easily end up with hundreds or even thousands of words and variations, so you somehow need to limit them. One group of words I left out are those referring to genitals, because there is such a wealth of expressions and running some queries indicated that they are used rarely in commit messages.
To only include frequently used words, I searched for references and found this article about the most popular swear words on network TV in 2010. I created the following regular expression based on it with a few words and acronyms added.
Regular Expression
(?i)\b(wtf|wth|omfg|hell|ass|bitch|bullshit|bloody|fucking?|shit+y?|crap+y?)\b|\b(fuck|damn|piss|screw|suck)e?d?\b
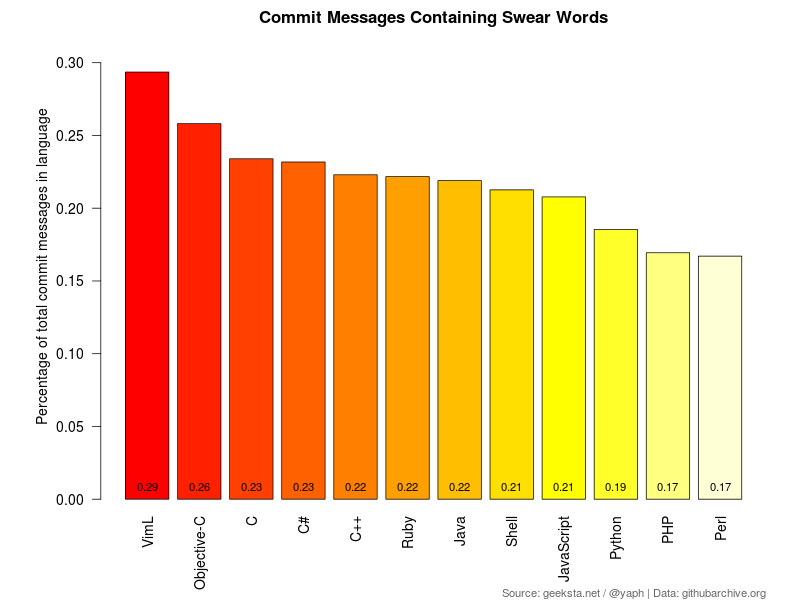
Example messages
- Whitespace commit: damn you all to hell (Java)
- Fuck the last database designer. (C#)
- fuck you php. (PHP)
- + Broken all the internet rules. FUCK YOU H1 (PHP)
- screw you guys, Im going home (Java)
- date parsing hell (Ruby)
- Revert "Revert "crap, removed the code"" This reverts commit ... (Go)
- Fuck UTF8! (JavaScript)
- fuck the system (JavaScript)
- clean shit out of pasted text (JavaScript)
- fuck it. i'll do it live! (JavaScript) - Editor's note: Always a good idea :D
- fuck i shoulda done this ages ago (C)
- this will piss andy off (JavaScript)
- fuck fuck holy shit fuck I think I finally fixed my shitty git fuck (JavaScript)
- holy shit... it seems to work (PHP)
- Fixed stupid fucking shit (C#)
- Holy shit, the bloody bastard starts up. :) (Python)
- what in the fucking fuck: i am going insane (Ruby)
- No more fucking with me, AnnotationRegistry! (PHP)
- that fucking comma, it will get you every time (PHP)
- stupid fucking piece of shit (Perl)
- in short a big fucking headache (PHP)
Summary
Analyzing emotions in texts based on the occurrence of expressions is certainly a disputable approach. As stated above I am aware of several flaws that skew the results and do not claim that this descriptive study has any scientific value.
Improvements to the approach in order to get more reliable results that could serve as the basis for applying inferential methods and draw conclusions include:
- balanced sample sizes for the studied programming language
- more comprehensive lists of expressions
- natural language detection of messages
- review of all found candidates
- categorization of all sample messages by humans
What other improvements come to your mind and why do you think they'd work better? You can leave feedback by creating an issue in the project's GitHub repo, which contains the database queries and scripts for calculating percentages and generating charts used in this article.
Instead of ending with a statement like "X is the most friendly language because of Y", which wasn't my intention anyway, I conclude that exploring GitHub data can be a lot of fun and I'm curious to see what other developers get out of the GitHub Archive.
Language Resources
Update
Denis Roussel who made the well-deserved 1st place in the challenge with his awesome GitHub activity dashboard Octoboard recently integrated emotions, issues and swearing in his tool.
The original Octoboard has been discontinued.
Featured Merch

Latest Posts
- Social Media Dimensions Cheat Sheet 2026
- How to Check if an IP Address is Blocked on Linux
- How to Inspect All Cron Jobs on a Linux System: A Sysadmin's Guide
- Building a 3D Elevation Photo Diary with deck.gl
- Thunderbird Keeps Threading Emails? Here's the Fix
Featured Book

Subscribe to RSS Feed
Published by Ramiro Gómez on . Subscribe to the Geeksta RSS feed to be informed about new posts.
Tags: regular expressions github data analysis git
Disclosure: External links on this website may contain affiliate IDs, which means that I earn a commission if you make a purchase using these links. This allows me to offer hopefully valuable content for free while keeping this website sustainable. For more information, please see the disclosure section on the about page.




